해외 유명 편집샵인 매치스패션,마이테레사,컬티즘,육스 웹 사이트에서 세일하고 있는 제품을 Python을 활용하여 데이터를 추출하고 csv파일로 저장해보겠습니다.
1. 라이브러리 설치
requests 모듈은 간단한 HTTP 요청 처리를 위해 사용된다.
pip install requestsHTML 태그를 파싱 하여 사진, 글, 콘텐츠를 사용자가 편리하게 가져올 수 있게 제공해준다.
pip install beautifulsoup4lxml은 XML 및 HTML을 구문 분석하기 위한 매우 간단하고 강력한 API를 제공한다.
pip install lxml
2. 웹 페이지 접속
유명한 해외 쇼핑몰인 매치스패션에 세일 중인 상품들을 크롤링해보겠습니다.
먼저 url 주소를 GET 요청을 보내서 서버에서 응답을 받을 수 있는지 확인해 보겠습니다. 응답 코드가 200이면 정상 동작했다는 것을 알 수 있습니다.
import requests
url = "https://www.matchesfashion.com/kr/mens/apac-sale?page=1&noOfRecordsPerPage=240&sort="
res = requests.get(url)
res.raise_for_status()
print("응답코드 :",res.status_code)
HTTP 오류 429 발생했습니다. 웹사이트에서는 접속을 하는 사용자들의 정보를 알 수가 있는데 이것이 헤더 정보입니다. 만약 사람의 접속하는 것이 아닌 정보로 판단될 경우 접속을 차단시켜버립니다. 이를 해결하기 위해서 User-Agent를 사용해야 됩니다.

크롬에 useragent string을 검색해서 첫 번째로 뜨는 WhatIsMyBrowser.com에서 정보를 확인하고 복사해줍니다.

해당 url로 접속할 때 user-agent 값을 같이 넘겨줍니다. 이렇게 하면 우리가 실제로 크롬에서 접속하는 것과 동일한 정보를 받아 올 수 있습니다.
import requests
url = "https://www.matchesfashion.com/kr/mens/apac-sale?page=1&noOfRecordsPerPage=240&sort="
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36"}
res = requests.get(url,headers=headers)
res.raise_for_status()
print("응답코드 :",res.status_code)
3. 웹 페이지 분석
오른쪽 상단을 페이지 수를 확인해보니 1~17페이지 까지 존재하는 것을 확인할 수 있습니다.

F12를 눌러서 페이지 수를 클릭해보면 <u> 태그 안에 하위 <li> 태그들이 존재하고 그 아래 <a> 태그가 존재하는 것을 확인할 수 있습니다. 저는 모든 페이지에 제품들을 크롤링해야 됨으로 <a> 태그 안에 17이라는 텍스트 값만 추출해보겠습니다.

BeautifulSoup의 메서드로 find와 select을 사용해서 원하는 값을 찾을 수 있다. 간단히 find와 select이 무엇인지만 알아보겠습니다.
find 설명

- find() - 조건을 만족하는 태그를 하나만 가져오는 함수이다.
- find_all() - 태그가 여러 개 있을 경우 해당하는 태그를 한꺼번에 가져오는 함수이다.
- string - find 함수로 가져온 태그 정보에서 문장을 가져온다.
- get_text() - find 함수로 가져온 태그 정보에서 문장을 가져온다. string과 차이점은 string의 경우 문자열이 없으면 None을 출력하고, get_text()는 아무 정보도 출력하지 않는다.
select 설명
- select_one() - 조건에 맞는 태그를 한 개 가져오는 함수이다.
- select() - 조건에 맞는 태그를 여러 개 가져오는 함수이다.
find와 select 간단한 차이를 보면 find의 경우 반복적으로 코드를 작성해야 되지만 select은 직접 하위 경로를 지정할 수 있기 때문에 간편하다. 아래 링크를 참고하면 자세히 설명되어있습니다. (한국어 번역 가능!)
Beautiful Soup Documentation — Beautiful Soup 4.9.0 documentation (crummy.com)
#find
soup.find('div').find('p')
#select
soup.select_one('div > p')
다시 돌아와서 코드를 보면 select 함수를 사용해서 <ul> 태그의 class명으로 찾은 다음 그 하위 태그인 li > a 태그를 찾았습니다. 그런 다음 select로 여러 개의 태그 정보를 가지고 오면 list로 반환이 된다. list에서 <a> 태그 중에 세 번째 요소에 text 값만 추출한다.
import requests
from bs4 import BeautifulSoup
url = "https://www.matchesfashion.com/kr/mens/apac-sale?page=1&noOfRecordsPerPage=240&sort="
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36"}
res = requests.get(url,headers=headers)
res.raise_for_status()
soup = BeautifulSoup(res.text, "lxml")
link = soup.select('.redefine__right__pager > li > a')
print(link[2].text)
웹 페이지 url을 확인해보니 2번째 페이지를 클릭하면 https://www.matchesfashion.com/us/mens/apac-sale?page=2&noOfRecordsPerPage=240&sort=
page=2 로 변환 것을 확인할 수 있습니다

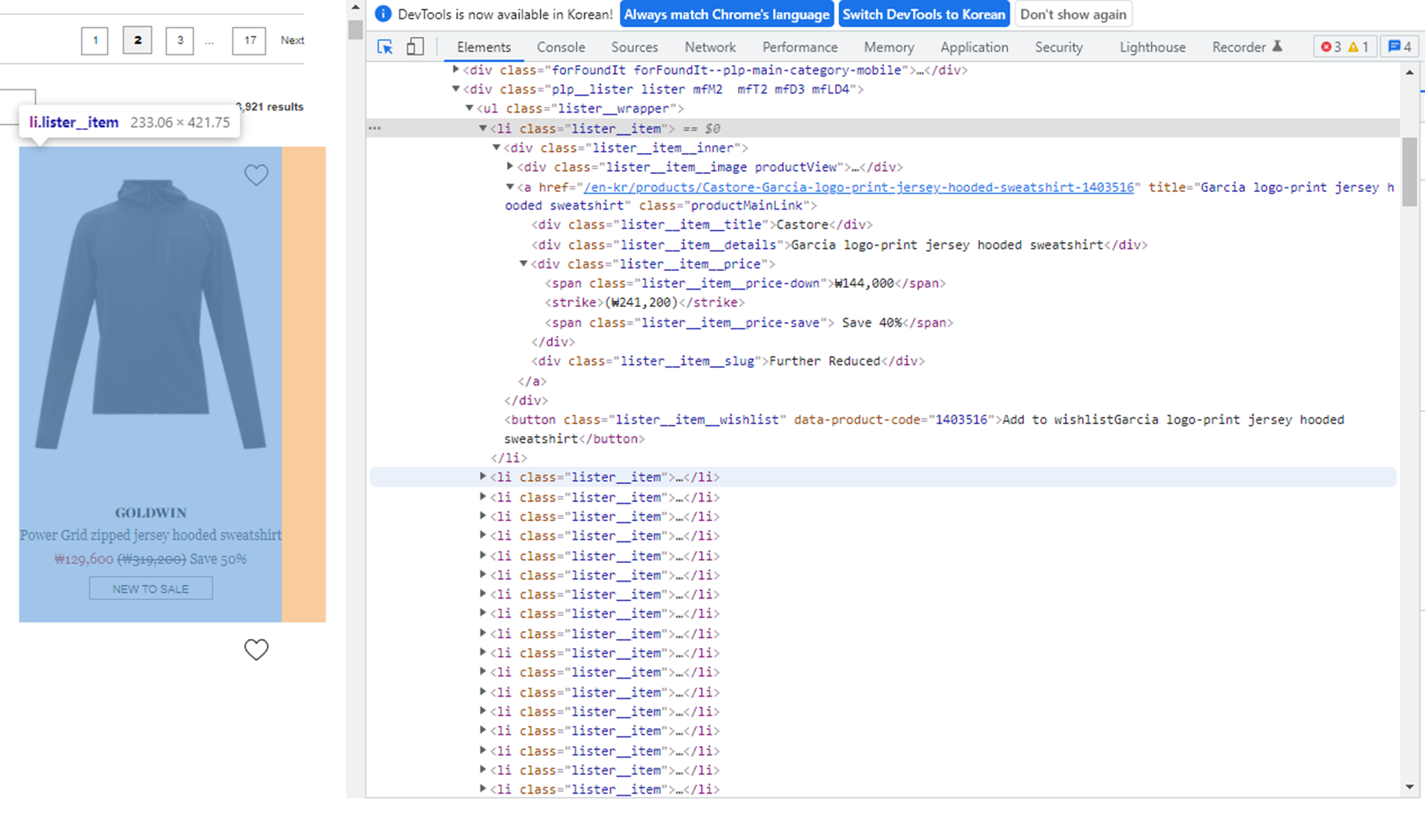
그리고 각 제품마다 <li> 태그인 class=lister__item으로 감싸져 있는 것을 확인할 수 있습니다. 그러면 반복문을 사용해서 1~17 페이지의 제품 정보를 추출해보겠습니다.
for i in range(1,int(link[2].text)+1):
res = requests.get(f"https://www.matchesfashion.com/us/mens/apac-sale?page={i}&noOfRecordsPerPage=240&sort=",headers=headers)
soup = BeautifulSoup(res.text, "html.parser")
item = soup.find_all('li',{'class':'lister__item'})
print(item)
item안에 GOLDWIN이라는 제품이 태그 정보들을 잘 갖고 온 것을 확인할 수 있습니다.

이제 item에서 제품의 브랜드명, 제품명, 가격, 할인 가격 정보를 추출해보겠습니다.
import requests
from bs4 import BeautifulSoup
url = "https://www.matchesfashion.com/en-kr/mens/apac-sale?page=1&noOfRecordsPerPage=240&sort="
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36"}
res = requests.get(url,headers=headers)
res.raise_for_status()
soup = BeautifulSoup(res.text, "lxml")
link = soup.select('.redefine__right__pager > li > a')
print(link[2].text)
for i in range(1,int(link[2].text)+1):
res = requests.get(f"https://www.matchesfashion.com/us/mens/apac-sale?page={i}&noOfRecordsPerPage=240&sort=",headers=headers)
soup = BeautifulSoup(res.text, "lxml")
item = soup.find_all('li',{'class':'lister__item'})
for it in item:
# 제품정보
item_info = []
# 브랜드명
item_info.append(it.select_one('.lister__item__title').text)
# 아이템명
item_info.append(it.select_one('.lister__item__details').text)
# 가격
item_info.append(it.select_one('.lister__item__price > strike').text)
# 할인가격
item_info.append(it.select_one('.lister__item__price-down').text)
print(item_info)
결과를 보니 잘 추출한 것 같습니다. 하지만 나중에 db에 적재하고 데이터 분석을 하기 위해서는 추가 작업이 필요할 것 같습니다.

추가 작업 목록
- 브랜드명과 아이템명은 공백, 특수문자 제거하고 모두 소문자로 변환
- 가격은 특수문자를 제거하고 달러를 환화로 계산
- 편집 삽 명 추가
- 해당 아이템의 url을 추가
파이썬에서 re 모듈을 import 해서 사용할 수 있습니다.
re.sub (정규 표현식, 바꿀 문자열, 치환 문자)
- 정규 표현식 - 검색 패턴을 지정
- 바꿀 문자열 - 바꾸고 싶은 문자열
- 치환 문자 - 변경하고 싶은 문자
원하는 결과가 나오는지 다시 실행해보자.
import requests
import re
from bs4 import BeautifulSoup
url = "https://www.matchesfashion.com/en-kr/mens/apac-sale?page=1&noOfRecordsPerPage=240&sort="
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36"}
res = requests.get(url,headers=headers)
res.raise_for_status()
soup = BeautifulSoup(res.text, "lxml")
link = soup.select('.redefine__right__pager > li > a')
for i in range(1,int(link[2].text)+1):
res = requests.get(f"https://www.matchesfashion.com/en-kr/mens/apac-sale?page={i}&noOfRecordsPerPage=240&sort=",headers=headers)
soup = BeautifulSoup(res.text, "lxml")
item = soup.find_all('li',{'class':'lister__item'})
for it in item:
item_info = []
# 편집샵 명
shop_name = filename
item_info.append(shop_name)
# 브랜드명
item_brand = it.select_one('.lister__item__title').text
str_item_brand = re.sub('[^0-9a-zA-Z-./ ]','',item_brand)
item_info.append(str_item_brand.strip().lower())
# 아이템명
item_name = it.select_one('.lister__item__details').text
str_item_name = re.sub('[^0-9a-zA-Z-./ ]','',item_name)
item_info.append(str_item_name.strip().lower())
# 정가
str_price = it.select_one('.lister__item__price > strike').text
num_price = re.sub('[^0-9]','', str_price)
# 달러 계산
float_price = round(float(num_price) * 1216.92)
item_info.append(float_price)
# 할인가격
str_down_price = it.select_one('.lister__item__price-down').text
num_down_price = re.sub('[^0-9]','',str_down_price)
# 달러 계산
float_price = round(float(num_down_price) * 1216.92)
item_info.append(float_price)
# 제품url
item_url="https://www.matchesfashion.com/" + it.select_one('div.lister__item__inner div a')['href']
item_info.append(item_url)
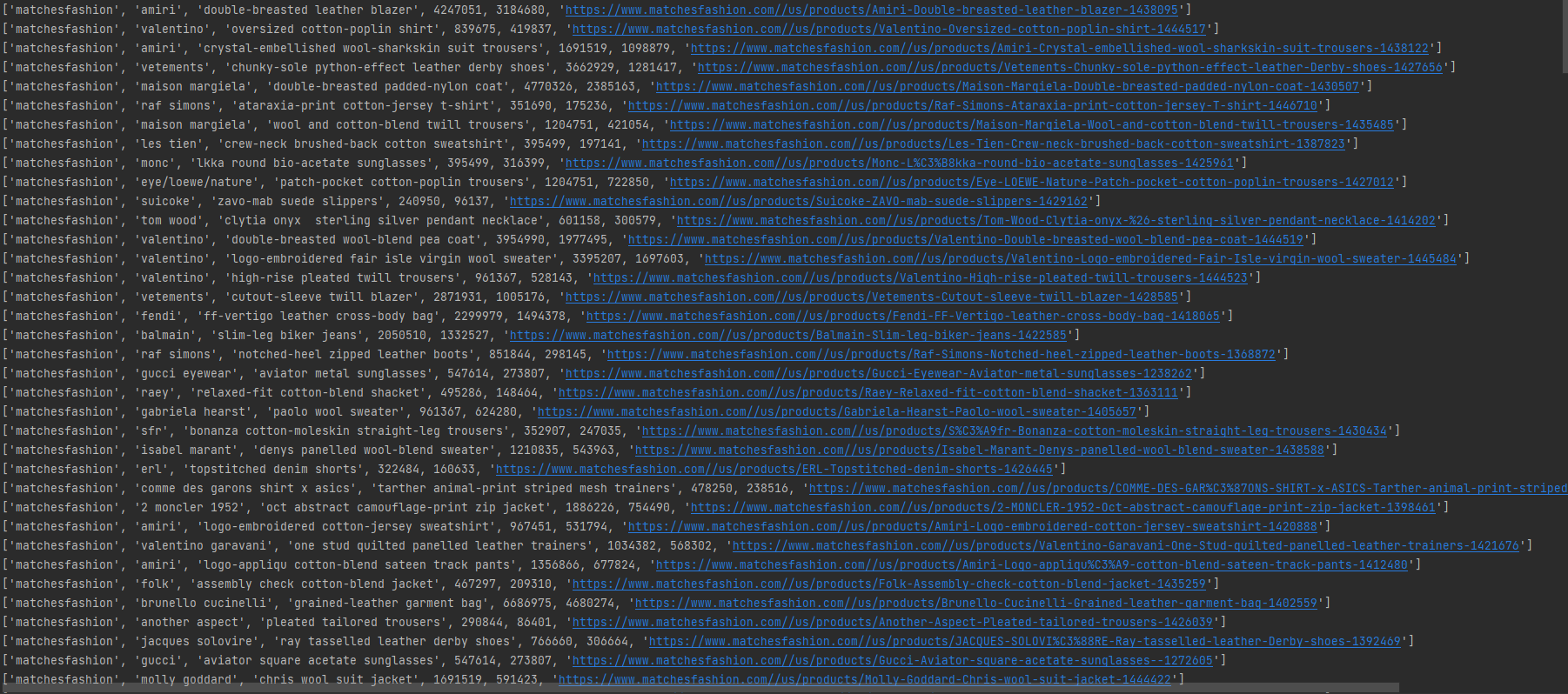
print(item_info)
원하는 데로 잘 추출된 것 같습니다. 이제 csv 파일로 저장해보겠습니다.
파이썬으로 csv를 다루려면 먼저 csv 모듈을 import를 해줘야 합니다. 그런 다음 파이썬 내장 함수인 open을 사용하여
파일 객체 = open(파일 이름, 파일 열기 모드, 인코딩 지정, 줄 바꿈 제거) , newline='' 사용하면 엑셀에 한 행씩 쓰일 때마다 줄 바꿈 되는 것을 막을 수 있습니다.
| 파일 열기모드 | 설명 |
| r | 읽기모드 - 파일을 읽기만 할 때 사용 |
| w | 쓰기모드 - 파일에 내용을 쓸 때 사용 |
| a | 추가모드 - 파일의 마지막에 새로운 내용을 추가 시킬 때 사용 |
matchesfasion.py
import requests
import re
import csv
from bs4 import BeautifulSoup
url = "https://www.matchesfashion.com/en-kr/mens/apac-sale?page=1&noOfRecordsPerPage=240&sort="
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36"}
res = requests.get(url,headers=headers)
res.raise_for_status()
soup = BeautifulSoup(res.text, "lxml")
link = soup.select('.redefine__right__pager > li > a')
filename = "matchesfashion.csv"
f = open(filename,"w",encoding="utf-8-sig",newline="")
writer = csv.writer(f)
# 액셀 타이틀 제목
title ="item_brand item_name item_price item_down_price".split()
# writerow() 메서드를 통해 list 데이터를 한 라인 추가
writer.writerow(title)
for i in range(1,int(link[2].text)+1):
res = requests.get(f"https://www.matchesfashion.com/en-kr/mens/apac-sale?page={i}&noOfRecordsPerPage=240&sort=",headers=headers)
soup = BeautifulSoup(res.text, "lxml")
item = soup.find_all('li',{'class':'lister__item'})
for it in item:
item_info = []
# 편집샵 명
shop_name = filename
item_info.append(shop_name)
# 브랜드명
item_brand = it.select_one('.lister__item__title').text
str_item_brand = re.sub('[^0-9a-zA-Z-./ ]','',item_brand)
item_info.append(str_item_brand.strip().lower())
# 아이템명
item_name = it.select_one('.lister__item__details').text
str_item_name = re.sub('[^0-9a-zA-Z-./ ]','',item_name)
item_info.append(str_item_name.strip().lower())
# 정가
str_price = it.select_one('.lister__item__price > strike').text
num_price = re.sub('[^0-9]','', str_price)
# 달러 계산
float_price = round(float(num_price) * 1216.92)
item_info.append(float_price)
# 할인가격
str_down_price = it.select_one('.lister__item__price-down').text
num_down_price = re.sub('[^0-9]','',str_down_price)
# 달러 계산
float_price = round(float(num_down_price) * 1216.92)
item_info.append(float_price)
# 제품url
item_url="https://www.matchesfashion.com/" + it.select_one('div.lister__item__inner div a')['href']
item_info.append(item_url)
# 파일 저장
writer.writerow(item_info)
4. 최종소스 코드
매치스패션에서 데이터를 추출하는 작업은 끝났습니다. 하지만 다른 사이트 마이테레사,컬티즘,육스에서도 비슷한 형태로 작업을 해야 됩니다. 코드의 가독성과 유지보수를 위해 코드 구조를 수정하겠습니다.
먼저 공통적으로 사용되는 코드를 함수를 만들어서 작업하겠습니다
file_save.py
import csv
import datetime
from file_settings.directory_create import createFolder
# 수집 날짜
collection_date = datetime.datetime.now().date()
# 파일 저장 함수
def file_save(filename):
# 파일 이름
filename = "{}_{}.csv".format(filename,collection_date)
# 디렉토리 생성
createFolder("C:/Users/YONG/PycharmProjects/ smart_shopping/crawling/data/{}/".format(collection_date))
# 저장 경로
path = "C:/Users/YONG/PycharmProjects/ smart_shopping/crawling/data/{}/".format(collection_date) + filename
# 파일 열기
f = open(path, "w", encoding="utf-8-sig", newline="")
writer = csv.writer(f)
# 타이틀 제목
title ="shop_name item_brand item_name item_price item_down_price item_url".split()
writer.writerow(title)
return writer
web_connection.py
import requests
from bs4 import BeautifulSoup
# 웹 페이지 접속 함수
def web_connection(url,headers):
try:
res = requests.get(url, headers=headers)
res.raise_for_status()
soup = BeautifulSoup(res.text, "lxml")
except Exception as e:
print(e)
else:
return soup
디렉터리를 생성하여 파일을 관리하는 함수와 S3에 업로드하는 함수를 추가하겠습니다.
direcotory_create.py
import os
# 디렉토리 생성 함수
def createFolder(directory):
try:
if not os.path.exists(directory):
os.makedirs(directory)
except OSError:
print('Error: Creating directory. ' + directory)
s3 업로드 작업은 아래 포스팅을 참고 부탁드립니다.
[AWS] Python으로 AWS S3에 이미지 파일 업로드 (tistory.com)
s3_connection.py
import boto3
from file_settings import file_save
# s3 접속 함수
def s3_connection():
try:
s3 = boto3.client(
service_name="s3",
region_name="ap-northeast-2",
aws_access_key_id="{액세스 키 ID}",
aws_secret_access_key="{보안 액세스 키}",
)
except Exception as e:
print(e)
else:
print("s3 bucket connected!")
return s3
# S3로 파일 업로드 함수
def s3_upload_file(filename):
s3 = s3_connection()
filename = "{}_{}.csv".format(filename, file_save.collection_date)
try:
s3.upload_file("data/{}/{}".format(file_save.collection_date, filename),
"s3-yong",
"smart_shopping_data/{}/{}".format(file_save.collection_date, filename))
except Exception as e:
print(e)
마지막으로 수정된 matchefasion.py입니다.
matchesfasion.py
import re
from connection.s3_connection import *
from connection.web_connection import *
from file_settings.file_save import *
# 웹 접속
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36"}
url = "https://www.matchesfashion.com/us/mens/apac-sale?page=1&noOfRecordsPerPage=240&sort="
soup = web_connection(url,headers)
# 파일 이름
filename = "matchesfashion"
# 파일 저장
writer = file_save(filename)
# 마지막 페이지 길이
link = soup.select('.redefine__right__pager > li > a')
for i in range(1,int(link[2].text)+1):
soup = web_connection(f"https://www.matchesfashion.com/us/mens/apac-sale?page={i}&noOfRecordsPerPage=240&sort=",headers=headers)
item = soup.find_all('li',{'class':'lister__item'})
for it in item:
item_info = []
# 편집샵 명
shop_name = filename
item_info.append(shop_name)
# 브랜드명
item_brand = it.select_one('.lister__item__title').text
str_item_brand = re.sub('[^0-9a-zA-Z-./ ]','',item_brand)
item_info.append(str_item_brand.strip().lower())
# 아이템명
item_name = it.select_one('.lister__item__details').text
str_item_name = re.sub('[^0-9a-zA-Z-./ ]','',item_name)
item_info.append(str_item_name.strip().lower())
# 정가
str_price = it.select_one('.lister__item__price > strike').text
num_price = re.sub('[^0-9]','', str_price)
# 달러 계산
float_price = round(float(num_price) * 1216.92)
item_info.append(float_price)
# 할인가격
str_down_price = it.select_one('.lister__item__price-down').text
num_down_price = re.sub('[^0-9]','',str_down_price)
# 달러 계산
float_price = round(float(num_down_price) * 1216.92)
item_info.append(float_price)
# 제품url
item_url="https://www.matchesfashion.com/" + it.select_one('div.lister__item__inner div a')['href']
item_info.append(item_url)
# 파일 저장
writer.writerow(item_info)
# s3 파일 업로드
s3_upload_file(filename)
마무리
이번 실습을 통해 Python을 활용하여 간단한 ETL 작업을 경험하면서 데이터의 흐름을 알아서 좋았던 것 같습니다. 이번 포스팅에서는 다른 사이트 클롤링 작업이 비슷한 구조임으로 매치스패션 웹 사이트에 대해서만 포스팅하고 나머지 작업은 Github 저장소에 저장 해 놓았습니다. 감사합니다
'Language > Python' 카테고리의 다른 글
| [Python] Pandas 기초 및 실습 (0) | 2022.03.14 |
|---|---|
| [Python] input()함수로 값 여러개 입력 받기 (0) | 2022.01.17 |
| [Python] 패키지(package)와 모듈(module) 알아보기 (0) | 2022.01.16 |